Projects
For more details, please click on the ABS and Code sections. My full name is Jiwoong Choi, but I go by Gio.
2025
-
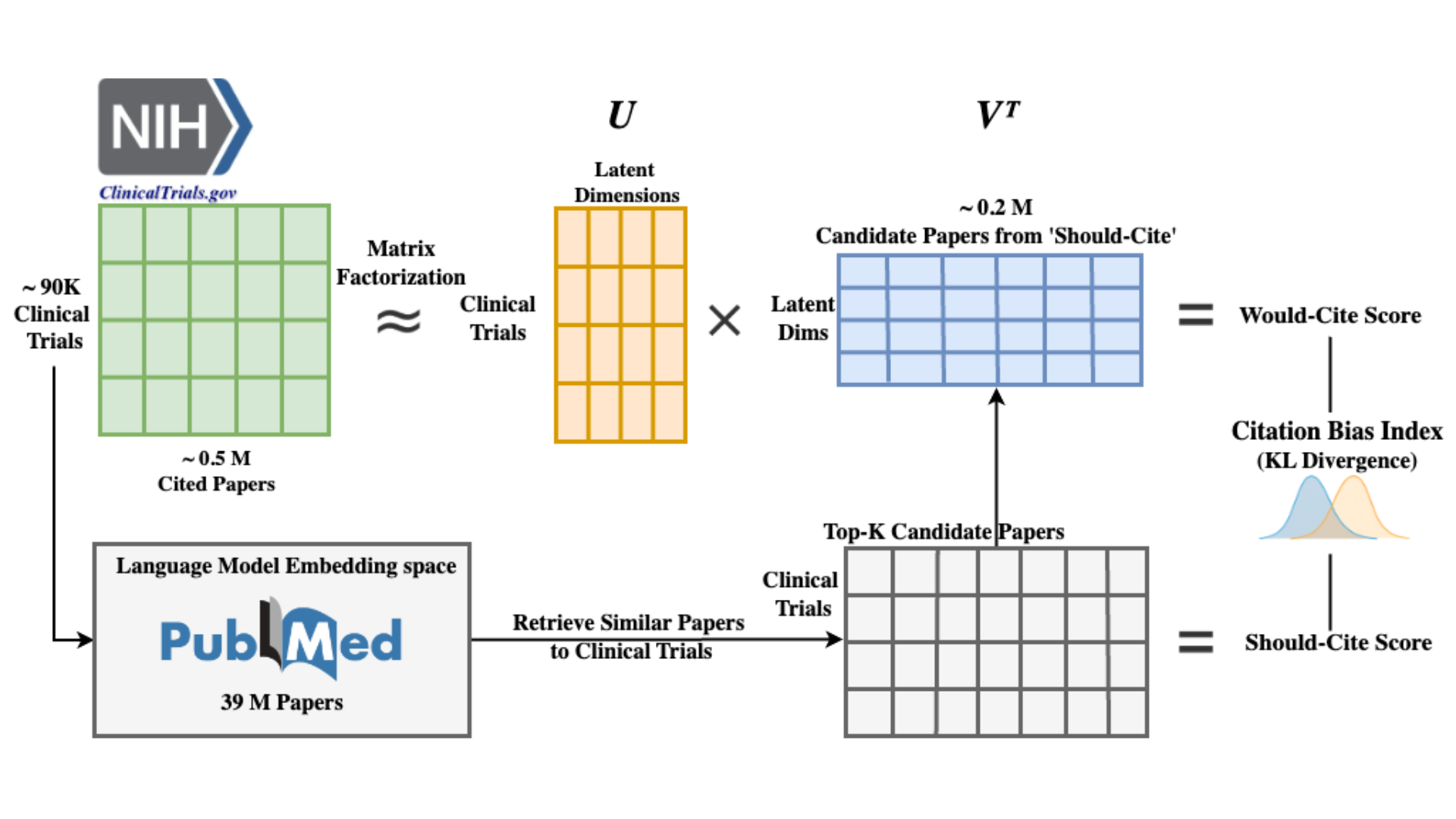 What Would Clinical Trials Cite — and What Should They Cite? Citation Bias and the p-value Heap in Clinical ResearchJiwoong ChoiWorking Paper (MA Thesis), Manuscript Ready, 2025
What Would Clinical Trials Cite — and What Should They Cite? Citation Bias and the p-value Heap in Clinical ResearchJiwoong ChoiWorking Paper (MA Thesis), Manuscript Ready, 2025Citations in clinical trial registrations do more than acknowledge prior work; they define the evidentiary context in which regulators and clinicians interpret results. I use this role to construct a trial-level Citation Bias Index (CBI) that measures how far a trial’s background citations at registration depart from the set of studies it ought to cite given pre-results information. Using 547,866 interventional trials on ClinicalTrials.gov linked to 39 million PubMed papers, I apply language model embeddings to identify content-relevant prior trials and systematic reviews (a “should-cite” set) and a matrix factorization model of the trial–paper citation network to estimate citation probabilities over candidate prior papers for the focal trial (a “would-cite” distribution). CBI is the symmetric Kullback–Leibler divergence between these distributions. Citation bias is lowest for trials that later report highly significant results (p ≤ 0.01) and spikes sharply for borderline findings just below p = 0.05, creating a pronounced p-value heap. In regressions with registration-year and condition fixed effects, higher CBI predicts a significantly greater probability that the trial’s outcome falls in the narrow borderline band (0.045 < p ≤ 0.05).
-
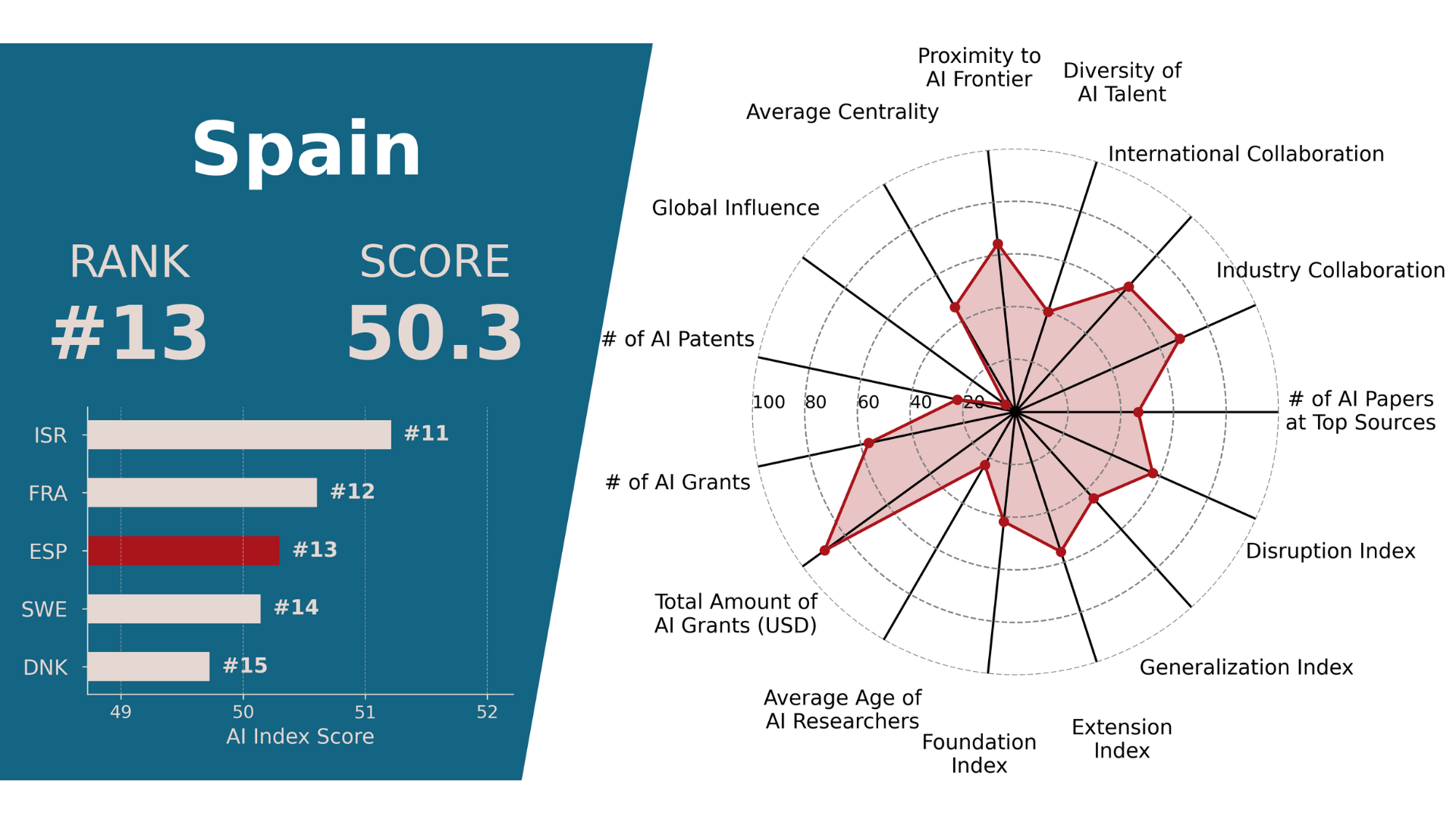 BReady4AI: Global AI Innovation IndexWorking Project, World Bank, 2025
BReady4AI: Global AI Innovation IndexWorking Project, World Bank, 2025We construct an annual, country-level AI innovation index organized around three pillars: Production of AI, Consumption of AI, and Participation in AI. Using indicators built from publications, patents, grants, collaboration networks, and demographic diversity, we score and rank countries on their capacity for frontier AI innovation.
-
 Language Models Surface the Unwritten Code of Science and SocietyHonglin Bao, Siyang Wu*, Jiwoong Choi*, Yingrong Mao*, and James A. EvansSubmitted to ACL 2026, Dec 2025
Language Models Surface the Unwritten Code of Science and SocietyHonglin Bao, Siyang Wu*, Jiwoong Choi*, Yingrong Mao*, and James A. EvansSubmitted to ACL 2026, Dec 2025This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society’s "unwritten code" - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating self-consistent hypotheses - why one paper appeared stronger in reviewer scoring - among paired papers submitted to 45 computer science conferences, while iteratively searching deeper hypotheses from remaining pairs where existing hypotheses cannot explain. We observed that LLMs’ normative priors about the internal characteristics of good science extracted from their self-talk, e.g. theoretical rigor, were systematically updated toward posteriors that emphasize storytelling about external connections, such as how the work is positioned and connected within and across literatures. This shift reveals the primacy of scientific myths about intrinsic properties driving scientific excellence rather than extrinsic contextualization and storytelling that influence conceptions of relevance and significance. Human reviewers tend to explicitly reward aspects that moderately align with LLMs’ normative priors (correlation = 0.49) but avoid articulating contextualization and storytelling posteriors in their review comments (correlation = -0.14), despite giving implicit reward to them with positive scores. We discuss the broad applicability of the framework, leveraging LLMs as diagnostic tools to surface the tacit codes underlying human society, enabling more precisely targeted responsible AI.
-
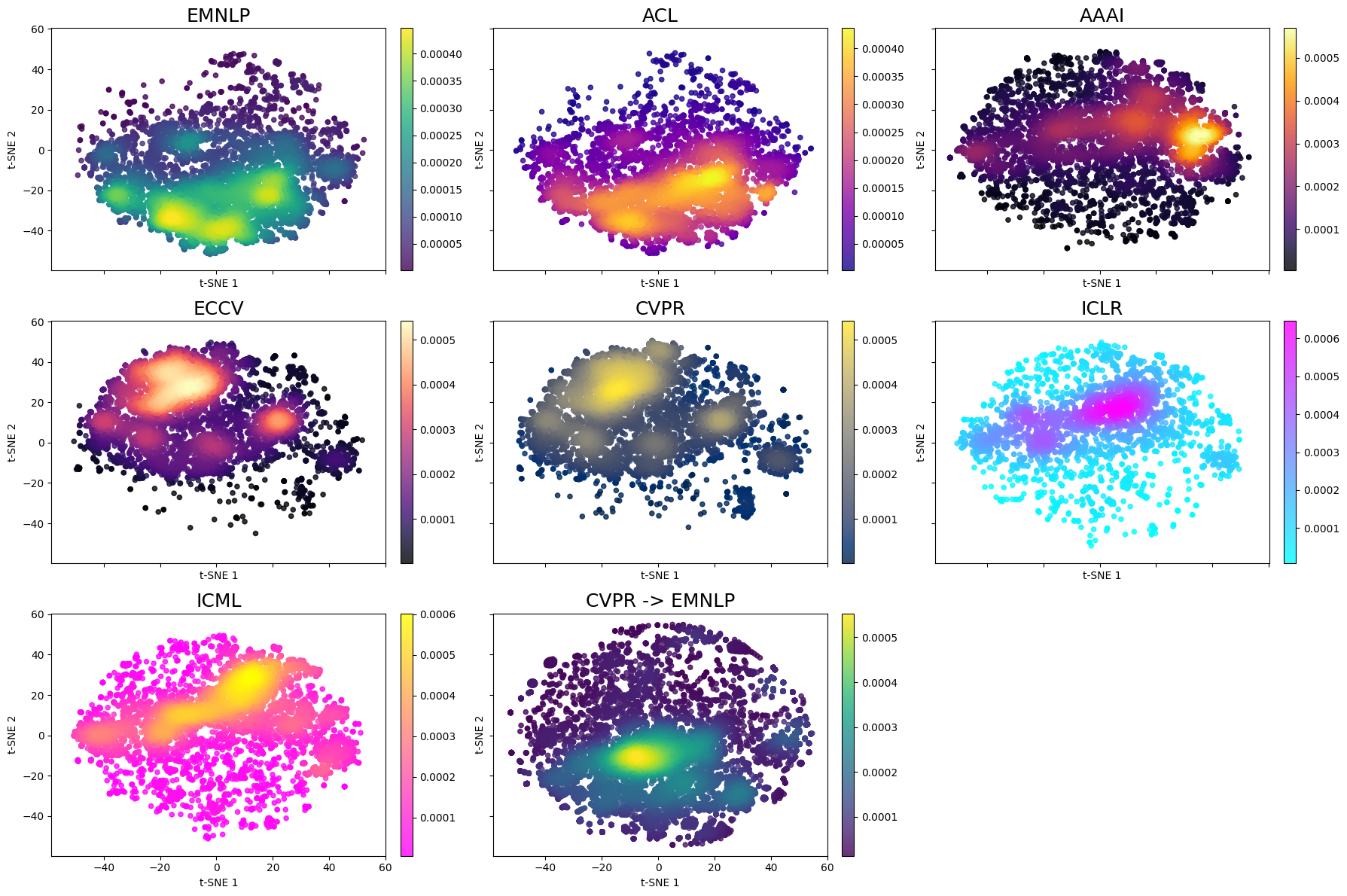 Academic Simulacra: Forcasting Research Ideas through Multi-Agent LLM SimulationsJiwoong Choi, Yingrong Mao, Donghyun Kang, and James EvansPoster Presentation at ACM Collective Intelligence 2025; Submitted to The Web Conference (WWW 2026), Aug 2025
Academic Simulacra: Forcasting Research Ideas through Multi-Agent LLM SimulationsJiwoong Choi, Yingrong Mao, Donghyun Kang, and James EvansPoster Presentation at ACM Collective Intelligence 2025; Submitted to The Web Conference (WWW 2026), Aug 2025Keywords: Multi-Agent Simulation, Simulated Scholarship, Large Language Models
Large language models (LLMs) trained on massive corpora of human knowledge show strong abilities in reasoning, question answering, and knowledge synthesis. Linked to large-scale scholarly records, they can approximate scientific trajectories and plausible alternatives. We present a framework that simulates scholarly conversations among multi-agent LLMs instantiated as digital twins of real researchers, each grounded in publication histories. Modeling 8,269 authors of 2024 papers across nine flagship computer-science conferences, agents propose and refine hypothetical 2024 research ideas beyond the models’ knowledge cutoff. Generated ideas are compared with actual papers using semantic-similarity and convex-hull analyses at the author and conference levels. At the author level, cross-classification shows strong correspondence between generated and focal classifications (94.4% inside–inside; 85.3% outside–outside), indicating that simulations approximate researchers’ research directions. At the conference level, simulations produced at least one idea outside both 2023 and 2024 convex hulls for 99.1% of focal papers, but these ideas were more recombinatorial and less feasible than human-authored ones. Overall, the results suggest that LLM-based simulations mirror established patterns of scientific production but tend to extend into less immediately feasible directions, recombining existing ideas. -
 Automating Scholarly JudgmentJiwoong Choi, Siyang Wu, Yingrong Mao, and Honglin Bao(Oral Presentation) International Conference on the Science of Science and Innovation (ICSSI), Jun 2025
Automating Scholarly JudgmentJiwoong Choi, Siyang Wu, Yingrong Mao, and Honglin Bao(Oral Presentation) International Conference on the Science of Science and Innovation (ICSSI), Jun 2025Keywords: Automated Hypothesis Generation, Scientific Evaluation, Large Language Models
What constitutes good science remains a longstanding question in both philosophy and practice. Traditional peer review, for instance, has been critiqued for subjectivity, inconsistency, and potential bias. Recent advances in large language models (LLMs) offer a novel opportunity to re-examine this question at scale. Here, we analyze a dataset of approximately 27K papers submitted to 45 computer science conferences, paired on review scores to create clear distinctions in perceived quality. Rather than manually defining the criteria of “good” science, we task LLMs with iteratively proposing, testing, and refining hypotheses that explain why one paper might be judged as stronger than another. This yields a final pool of 20 orthogonal hypotheses with high coverage of pairs. Throughout this abductive reasoning process, the LLM’s initial “normative” prior beliefs (e.g., a good paper has high novelty) are updated into a posterior that reflects more professional-science criteria (e.g., a good paper tells a good story). LLMs could serve as powerful tools for uncovering latent patterns in how experts judge scientific work. Nevertheless, challenges remain. Interpretability is a critical bottleneck: while the iterative process yields human-understandable hypotheses, it relies on opaque LLM reasoning under the hood. In addition, substantial progress is still needed in guiding LLMs and humans toward a clearer understanding of what constitutes truly valuable science.





2024
-
 Korea Discount and Corporate GovernanceSK Kim, Ye Jun Kim, and Jiwoong ChoiMorgan Stanley Capital International (MSCI Inc., Jun 2024
Korea Discount and Corporate GovernanceSK Kim, Ye Jun Kim, and Jiwoong ChoiMorgan Stanley Capital International (MSCI Inc., Jun 2024This paper examines the "Board and Ownership and Control" Key Issue within the MSCI ESG Ratings Corporate Governance Theme, with a focus on board independence and adherence to the one-share-one-vote (OSOV) principle. Our analysis reveals significant governance challenges among Korean companies. Notably, less than half of the directors on Korean company boards are independent, a figure significantly lower than the global average of 66%. Additionally, 82% of Korean companies were flagged for Related Party Transactions (RPT), with smaller firms exhibiting lower board independence. Furthermore, Korean companies that deviated from the OSOV principle demonstrated weaker financial performance, with both return-on-equity (ROE) and price-to-book ratio (PBR) falling below the market average. These findings underscore the need for enhanced governance practices within Korean corporations to align more closely with global standards.
-
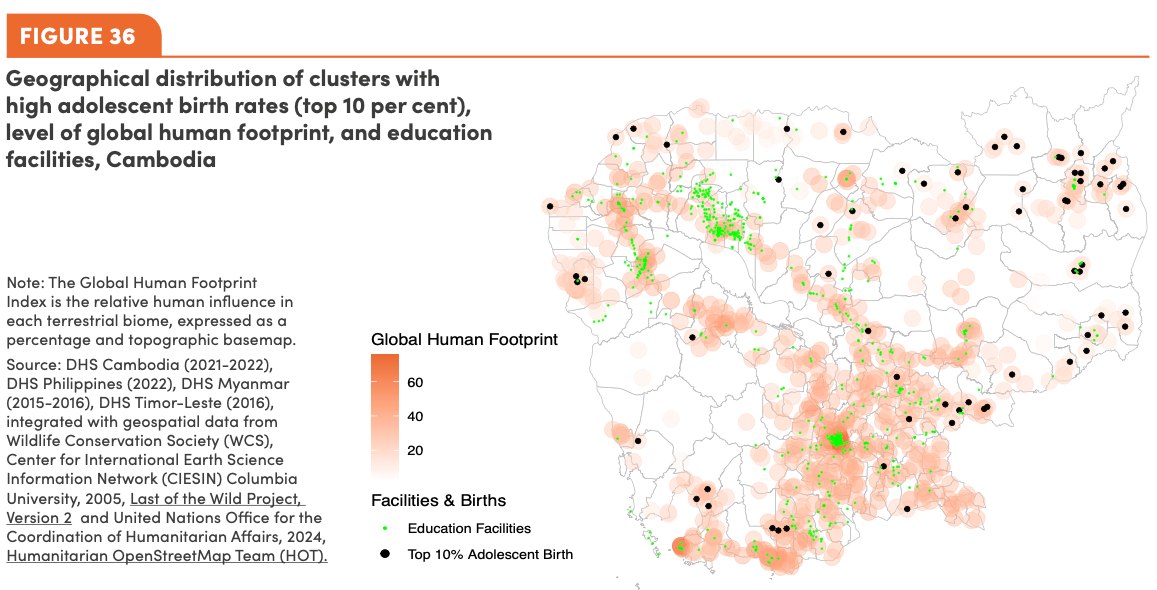 ASEAN Gender Outlook 2024Statistics-Jiwoong ChoiUN General Assembly (UNGA), Sep 2024
ASEAN Gender Outlook 2024Statistics-Jiwoong ChoiUN General Assembly (UNGA), Sep 2024- Despite high primary and lower secondary education completion rates in ASEAN, only 64 percent of students complete upper secondary education, with boys, particularly in rural areas, being more likely to drop out due to economic barriers and opportunity costs. While girls tend to stay in school longer, challenges such as inadequate access to employment opportunities, poor educational infrastructure, and disparities between urban and rural areas persist, highlighting the need for increased investments in education across the region.
- Adolescent birth rates in South-East Asia have decreased from 41 to 35 per 1,000 between 2015 and 2024, with factors such as delayed marriage, access to contraceptives, and education contributing to this decline. However, disparities in education infrastructure, particularly in rural areas, remain a challenge, with limited access to basic facilities like sanitation and water, which increases the likelihood of teenage pregnancy and school dropout among rural girls.
- Despite South-East Asia being one of the world’s safest regions with a homicide rate of 1.8 per 100,000 people, a growing sense of insecurity, particularly among women, has emerged due to factors like COVID-19, economic disruptions, and crime, highlighting the need for enhanced law enforcement and inclusive security approaches.
- Over the past decade, official development assistance (ODA) for gender equality in the ASEAN region has increased significantly, with 47% of all ODA in 2022 supporting gender-focused initiatives, though investments directly targeting gender equality have declined, highlighting the need for continued and expanded funding to sustain progress in areas like women’s participation, violence reduction, and the gender-environment nexus.

2022
-
 Outdoor visual SLAM and Path Planning for Mobile-RobotSeongil Heo, Jueun Mun, Jiwoong Choi, Jiwon Park, and Eric T. MatsonIEEE International Conference on Robotic Computing (IRC), Dec 2022
Outdoor visual SLAM and Path Planning for Mobile-RobotSeongil Heo, Jueun Mun, Jiwoong Choi, Jiwon Park, and Eric T. MatsonIEEE International Conference on Robotic Computing (IRC), Dec 2022This paper proposes a robust visual SLAM and a path planning algorithm for autonomous vehicles in the outdoor environment. The consideration of the outdoor characteristics was essential in both SLAM and path planning processes. This study can be used when it is necessary to know the exact appearance of the environment due to the impossibility of observing the environment through a satellite map, e.g., inside a forest. The visual SLAM system was developed using GPS data in consideration of the deterioration of camera recognition performance outdoors. The GPS data was inserted into every multi-thread of visual SLAM, which are Camera Tracking, Local Mapping, and Loop Closing. It enhanced the accuracy of the map and saved computational power by preventing useless calculations. In the path planning part, our method divided the path based on the stability of the roads. When determining the optimal path, the stability of the road and the driving time were considered, and the weight was assigned based on the GPS data.

2021
-
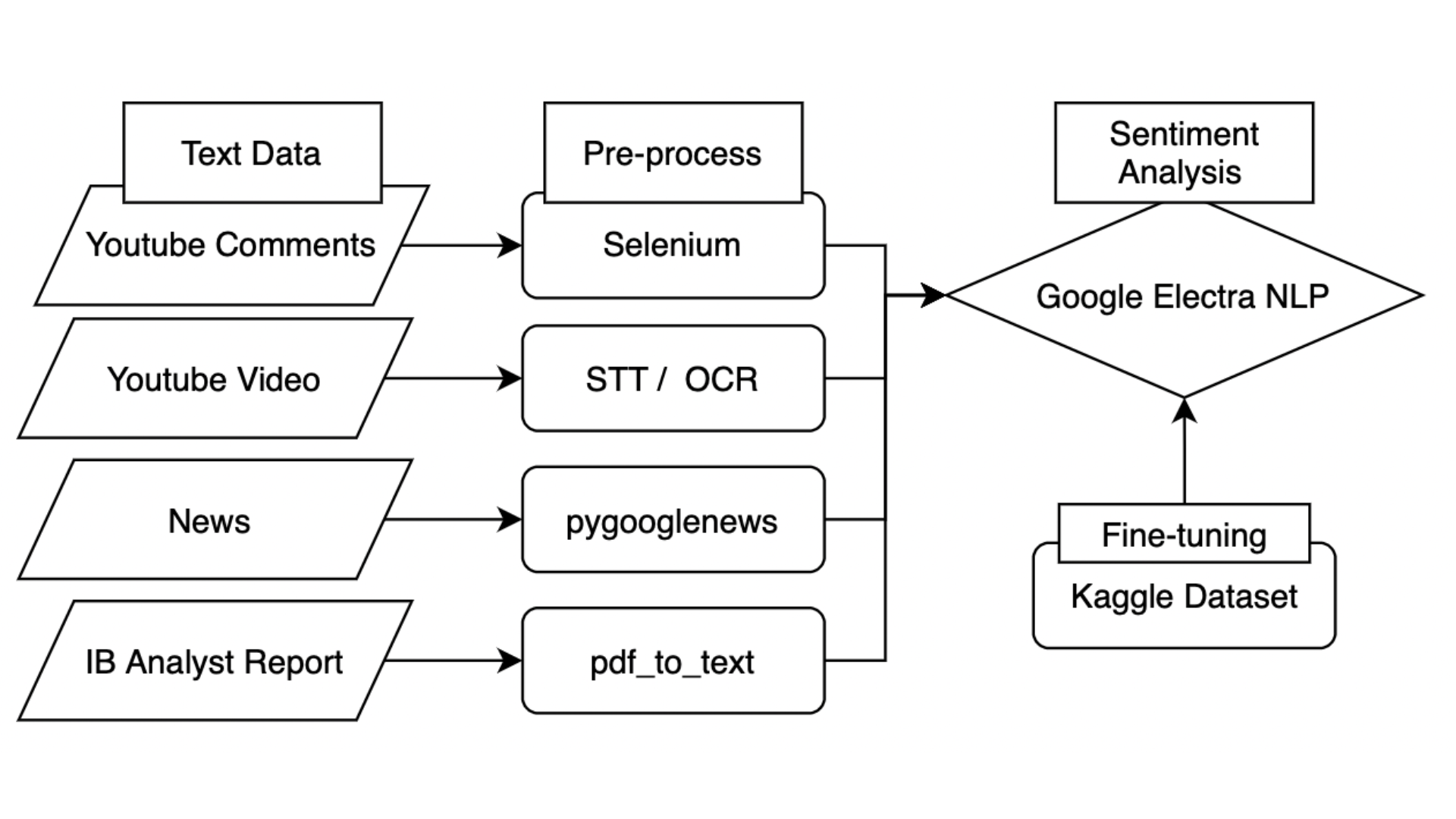 Stock Investment Opinion Sentimental AnalysisMirae Asset Big Data Hackathon, Nov 2021
Stock Investment Opinion Sentimental AnalysisMirae Asset Big Data Hackathon, Nov 2021- Collected text data from YouTube videos, YouTube comments, News, and Bank Reports by STT, OCR, and Crawling methods.
- Fine-tuned Google’s ELECTRA model which is a GAN-based transformer model by PyTorch.
- Conducted a Sentimental Analysis and made a prototype service.
- Gave a presentation on behalf of our team and finally achieved 4th place out of 1,000.
